NSUM module: name selection
Thijmen Jeroense
Last compiled on 26 februari, 2024
Network Scale Up (NELLS): Name analysis using Meertens Databank
In order to correctly create a module which we can use in the NELLS to measure the weak tie network we need to analyze the frequency of names. The names we eventually are going to use need to fulfill a view conditions and requirements. This HTML file documents the choices we make in creating the survey and it also provides easy reproducibility. Throughout we will use the guidelines as set out in (McCormick, Salganik, and Zheng 2010).
#list of packages that were used
library(tidyverse) #for data transformation
library(kableExtra) #for making nice tables
library(magrittr) #for data transformation
library(zoo) #for rolling average
library(cbsodataR) #for cbs data
library(patchwork)Name frequency
We scraped the Meertens first name databank with use of an altered script that Rense Corten shared with us. The databank consists of multiple sources. A yearly popularity lists of newborns first names, the frequency of names in 2014 population, the number of newborns with a given name for each year between 1880-2016. The scrape procedure is as follows. I first scraped the yearly popularity lists from 1920 untill 2016 to get an overview of the most used names for newborns. This list of names is then used to scrape the entire Meertens databank. For every name in this list I scraped its frequency in the total population and also the number of newborns per year with that name. These scrape scripts can be found on my Github.
First let’s look at all the names we have scrape from the meertens databank.
#import the data from the web scrape (with the gender handles)
namen_data <- read_csv("data_analysis/data/data_processed/meertens_scrape/all_names_19202014.csv")
#rename name into names and select only names and gender identifier.
namen_data <- namen_data %>%
rename(names = name) %>%
select(names, is_girl_name)
#add frequency of birth data to the name data frame.
voornamen_data <- read.csv("data_analysis/data/data_processed/meertens_scrape/dutch_names_frequency_18802016.csv")
#join the dfs togeteher,
voornamen_data <- namen_data %>%
left_join(voornamen_data, by = "names")
#reset all to utf8 coding. If I dont replace this then I wont be able to use group_by()
voornamen_data$names <- str_replace_all(voornamen_data$names,"[^[:graph:]]", " ")
#replace � with e. So all the names look prettier.
voornamen_data$names <- str_replace_all(voornamen_data$names, "�", "e")
#These are all names that were popular in the 1920-2014 timeframe.
unique(voornamen_data$names) %>%
kbl(caption = "Unique Names in period 1920-2014", col.names = "Names") %>%
kable_paper(full_width = F, bootstrap_options = c("hover", "condensed"), fixed_thead = T) %>%
scroll_box(height = "300px")| Names |
|---|
| Sophie |
| Emma |
| Julia |
| Mila |
| Tess |
| Isa |
| Zo<U+FFFD> |
| Eva |
| Fenna |
| Anna |
| Sara |
| Evi |
| Lynn |
| Lotte |
| Lisa |
| Fleur |
| Saar |
| Sarah |
| Lieke |
| Roos |
| Noa |
| Nora |
| Maud |
| Sanne |
| Sofie |
| Liv |
| Esmee |
| Noor |
| Yara |
| Elin |
| Amy |
| Milou |
| Nina |
| Anne |
| Olivia |
| Feline |
| Femke |
| Jasmijn |
| Nova |
| Jill |
| Naomi |
| Lo<U+FFFD>s |
| Liz |
| Vera |
| Eline |
| Emily |
| Floor |
| Luna |
| Benthe |
| Iris |
| Fenne |
| Lizzy |
| Lina |
| Elise |
| Hannah |
| Isabella |
| Norah |
| Evy |
| Lana |
| Lola |
| Tessa |
| Amber |
| Suze |
| Isabel |
| Julie |
| Fay |
| Sophia |
| Lara |
| Charlotte |
| Nikki |
| Veerle |
| Ella |
| Lauren |
| Bo |
| Maria |
| Fien |
| Sofia |
| Rosalie |
| Bente |
| Elif |
| Fiene |
| Suus |
| Mirthe |
| Linde |
| Anouk |
| Fem |
| Johanna |
| Amira |
| Ilse |
| Senna |
| Lise |
| Marit |
| Merel |
| Cato |
| Demi |
| Rosa |
| Indy |
| Hailey |
| Daan |
| Bram |
| Sem |
| Finn |
| Milan |
| Lucas |
| Luuk |
| Levi |
| Liam |
| Noah |
| Tim |
| Jayden |
| Thijs |
| Jesse |
| Thomas |
| Lars |
| Ruben |
| Max |
| Julian |
| Mees |
| Sam |
| Stijn |
| Siem |
| Tygo |
| Benjamin |
| Gijs |
| Sven |
| Hugo |
| Luca |
| Jens |
| Vince |
| Dex |
| Noud |
| Teun |
| Mats |
| Ryan |
| Adam |
| Jan |
| Tijn |
| Jurre |
| Floris |
| Cas |
| Boaz |
| Dani<U+FFFD>l |
| Senn |
| Ties |
| Joep |
| David |
| Jack |
| Guus |
| Roan |
| Olivier |
| Jason |
| Dani |
| Niek |
| Tom |
| Pim |
| Willem |
| Dean |
| Koen |
| Pepijn |
| Dylan |
| Thijmen |
| Fedde |
| Bas |
| Mason |
| Morris |
| Tobias |
| Mohammed |
| Mohamed |
| Joey |
| Pieter |
| Stan |
| Xavi |
| Hidde |
| Niels |
| Quinn |
| Jasper |
| Casper |
| Timo |
| James |
| Johannes |
| Jip |
| Nathan |
| Joris |
| Owen |
| Jelle |
| Mick |
| Aiden |
| Samuel |
| Damian |
| Hendrik |
| Robin |
| Cornelis |
| Daley |
| Rayan |
| Stef |
| Simon |
| Nick |
| Alexander |
| Puck |
| Nienke |
| Elisa |
| Romy |
| Isis |
| Laura |
| Jade |
| Elena |
| Sterre |
| Lize |
| Kyan |
| Joshua |
| Abel |
| Rens |
| Sepp |
| Jelte |
| Vaj<U+FFFD>n |
| Kiki |
| Myrthe |
| Yfke |
| Quinten |
| Justin |
| Keano |
| Fabian |
| Mika |
| Mike |
| Britt |
| Meike |
| Guusje |
| Pien |
| Job |
| Jonathan |
| Luc |
| Bart |
| Esm<U+FFFD>e |
| Isabelle |
| Danique |
| Quinty |
| Madelief |
| Noortje |
| Wessel |
| Wesley |
| Twan |
| Rick |
| Sander |
| Dylano |
| Maarten |
| Tristan |
| Kim |
| Renske |
| Kyra |
| Lisanne |
| Matthijs |
| Kevin |
| Silke |
| Maartje |
| Daphne |
| Elisabeth |
| Tara |
| Maaike |
| Marijn |
| Jesper |
| Gerrit |
| Mara |
| Nynke |
| Aya |
| Tycho |
| Martijn |
| Jacob |
| Floortje |
| Mare |
| Michelle |
| Merle |
| Melissa |
| Wouter |
| Mark |
| Jochem |
| Joost |
| Wout |
| Jamie |
| Youri |
| Carmen |
| Esther |
| Kirsten |
| Sjoerd |
| Jordy |
| Jarno |
| Dirk |
| Sil |
| Chris |
| Dennis |
| Megan |
| Denise |
| Gwen |
| Manon |
| Marieke |
| Mandy |
| Stefan |
| Jort |
| Jeroen |
| Roy |
| Dewi |
| Jennifer |
| Dani<U+FFFD>lle |
| Rachel |
| Suzanne |
| Donna |
| Rik |
| Sebastiaan |
| Vincent |
| Melanie |
| Cornelia |
| Kimberly |
| Chantal |
| Inge |
| Jo<U+FFFD>lle |
| Michael |
| Jeffrey |
| Bryan |
| Nikita |
| Sharon |
| Kelly |
| Joyce |
| Larissa |
| Kaylee |
| Simone |
| Mathijs |
| Brian |
| Danny |
| Britney |
| Linda |
| Samantha |
| Patrick |
| Ricardo |
| Mitchell |
| Marco |
| Remco |
| Sabine |
| Celine |
| Jessica |
| Rianne |
| Maxime |
| Kimberley |
| Ashley |
| Dominique |
| Judith |
| Fabi<U+FFFD>nne |
| Robert |
| Lorenzo |
| Jordi |
| Frank |
| Giovanni |
| Marinus |
| Cheyenne |
| Nicole |
| Tamara |
| Nathalie |
| Nadine |
| Steven |
| Dion |
| Marc |
| Dave |
| Yannick |
| Laurens |
| Marloes |
| Wendy |
| Adriana |
| Menno |
| Peter |
| Erik |
| Leon |
| Christiaan |
| Claudia |
| Loes |
| Janneke |
| Mariska |
| Marjolein |
| Saskia |
| Bob |
| Richard |
| Jari |
| Michiel |
| Priscilla |
| Cynthia |
| Rebecca |
| Catharina |
| Rob |
| Glenn |
| Mitchel |
| Paul |
| Melvin |
| Rutger |
| Johan |
| Stephanie |
| Daisy |
| Ellen |
| Marleen |
| Sandra |
| Leonie |
| Marije |
| Michel |
| Erwin |
| Jacobus |
| Bastiaan |
| Angela |
| Evelien |
| Brenda |
| Lisette |
| Pascal |
| Maikel |
| Robbert |
| Nicky |
| Bianca |
| Lianne |
| Yvonne |
| Wilhelmina |
| Patricia |
| Ilona |
| Shirley |
| Amanda |
| Roel |
| Petrus |
| Martinus |
| Nicolaas |
| Jimmy |
| Cindy |
| Stefanie |
| Nadia |
| Hendrika |
| Monique |
| Stephan |
| Davey |
| Marcel |
| Roxanne |
| Deborah |
| Miranda |
| Ren<U+FFFD> |
| Martin |
| Ronald |
| Adrianus |
| Leroy |
| Susanne |
| Karin |
| Sabrina |
| Mirjam |
| Ruud |
| Maurice |
| Elizabeth |
| Mari<U+FFFD>lle |
| Edwin |
| Wilhelmus |
| Franciscus |
| Arjan |
| Gerardus |
| Irene |
| Marijke |
| Petra |
| Jolanda |
| Petronella |
| Eveline |
| Hendrikus |
| Eric |
| Ingrid |
| Ren<U+FFFD>e |
| Marianne |
| Martine |
| Albert |
| Antonius |
| Nancy |
| Anita |
| Raymond |
| Hans |
| Jacoba |
| Angelique |
| Sylvia |
| Annemarie |
| Margaretha |
| Jacqueline |
| Christian |
| Arie |
| Klaas |
| Geert |
| Diana |
| Hanneke |
| Ivo |
| Barbara |
| Annemieke |
| Astrid |
| Vanessa |
| Christina |
| Renate |
| Harm |
| Paulus |
| Robertus |
| Natasja |
| Helena |
| Caroline |
| Susan |
| Rogier |
| Arjen |
| Bj<U+FFFD>rn |
| Ramona |
| Natascha |
| Adriaan |
| Guido |
| Barry |
| Sonja |
| Debby |
| Sandy |
| Ralph |
| Gerard |
| Marcus |
| Heidi |
| Ramon |
| Tanja |
| Alexandra |
| Miriam |
| Arno |
| Roelof |
| Frederik |
| Roland |
| Aaltje |
| Karen |
| Andr<U+FFFD> |
| Henricus |
| Mirella |
| Brigitte |
| Geertruida |
| Ingeborg |
| Antonia |
| Yvette |
| Grietje |
| Leendert |
| Emiel |
| Remko |
| Ester |
| Francisca |
| Danielle |
| Jantje |
| Theodorus |
| Albertus |
| Roger |
| Jurgen |
| John |
| Mireille |
| Geertje |
| Marion |
| Silvia |
| Eduard |
| Leonardus |
| Arnold |
| Bernardus |
| Monica |
| Anja |
| Henri<U+FFFD>tte |
| Edith |
| Alida |
| Janna |
| Herman |
| Rudolf |
| Mario |
| Manuela |
| Annette |
| Theodora |
| Belinda |
| Trijntje |
| Marjan |
| Lambertus |
| Ronny |
| Evert |
| Berend |
| Olaf |
| Harold |
| Hubertus |
| Irma |
| Antoinette |
| Carolina |
| Antje |
| Willemina |
| Agnes |
| Carla |
| Edward |
| Andreas |
| Arthur |
| Frans |
| Jeannette |
| Martina |
| Ang<U+FFFD>lique |
| Pauline |
| Nicolette |
| Pieternella |
| Neeltje |
| Arnoldus |
| Hermanus |
| Marie |
| Hendrikje |
| Henrica |
| Jannetje |
| Gerarda |
| Josephus |
| Teunis |
| Arend |
| Ferdinand |
| Margriet |
| Gerda |
| Josephina |
| Hermina |
| Joseph |
| Jozef |
| Andries |
| Johnny |
| D<U+FFFD>sir<U+FFFD>e |
| Gerritje |
| Gertruda |
| Ronaldus |
| Walter |
| Egbert |
| Paulina |
| Louise |
| Wilma |
| Christine |
| Dirkje |
| Martha |
| Hendricus |
| Marcellinus |
| Aart |
| Gijsbertus |
| Regina |
| Aleida |
| Anton |
| Karel |
| Abraham |
| Rudi |
| Lucia |
| Berendina |
| Theresia |
| Anneke |
| Joannes |
| Gerhardus |
| Yolanda |
| Marja |
| Hendrina |
| Jeanette |
| Harry |
| Gijsbert |
| Alfred |
| Paula |
| Hubertina |
| Brigitta |
| Bernard |
| Marina |
| Bernadette |
| Jantina |
| Veronica |
| Derk |
| Magdalena |
| Francina |
| Frederika |
| Janny |
| Everdina |
| Louis |
| Micha<U+FFFD>l |
| Gerdina |
| Dina |
| Gerritdina |
| Henriette |
| Joanna |
| Antonie |
| Reinier |
| Lena |
| Ida |
| Dorothea |
| Antoon |
| Jakob |
| Willy |
| Antonetta |
| Bertha |
| Engelina |
| Josepha |
| Louisa |
| Marius |
| Kornelis |
| Henri |
| Anthonius |
| Agatha |
| Jannigje |
| Marten |
| Christianus |
| Bertus |
| Hendrica |
| Henderika |
| Josephine |
| Cornelius |
| Fredericus |
| Clasina |
| Jannie |
| Geesje |
| Annie |
| Mathilda |
| Leo |
| Olga |
| Clara |
| Jansje |
| George |
| Dick |
| Nelly |
| Teuntje |
| Alberdina |
| Gertrudis |
| Laurentius |
| Godefridus |
| Gezina |
| Alphonsus |
| Klazina |
| Bernardina |
| Frits |
| Harmen |
| Elly |
| Bernhard |
| Gerhard |
| Elsje |
| Wilhelm |
| Alberta |
| Susanna |
| Grada |
| Annigje |
| Lodewijk |
| Ludovicus |
| Piet |
| Anthonie |
| Mathias |
| Beatrix |
| Willempje |
| Barend |
| Theo |
| Hubert |
| Aartje |
| Gerardina |
| Henderikus |
| Margje |
| Pietertje |
| Pietje |
| Jeltje |
| Harmina |
| Roelofje |
| Lammert |
| Hermannus |
| Willemijntje |
| Geertruda |
| Gesina |
| Allegonda |
| Mattheus |
| Janke |
| Anthonia |
| Huibert |
| Douwe |
| Jacomina |
| Trientje |
| Reinder |
| Aagje |
| Adriaantje |
| Hindrik |
| Bartholomeus |
| Gijsberta |
| Maatje |
| Otto |
| Johannis |
| Leentje |
| Gradus |
| Klaasje |
| Leonard |
Given that we have so many different names, it is fairly difficult to just choose a random number. We use the heuristics as set out in (McCormick 2010). As a start, we first need to get an overview of the different alter categories that we wish to include. These are gender, age, and ethnicity. For age, I will use four age categories: <25/25-40/41-65/65+. Gender consists of two categories: male/female. Ethnicity consists of Dutch native, Moroccan, and Turkish.
I will first turn to a the name frequency analysis for Dutch native names. In the second section I wil repeat this for the Moroccan and Turkish names.
Dutch Native Names
Given it is quite hard to eyeball the 763 names (period 1920 - 2014) we will make a first selection of names based on their frequency in the 2014 Dutch population. McCormick et al. specify that we want names that are not to frequent or infrequency (due to recall error). The ideal freuqency range is between 0.1 and 0.2 percentage of the population. We use the Dutch population of 2014 to calculate these frequencies. Unfortunately, we do not posses data on later years (as the Meertens databank has only information untill 2014).
Filter out names that are too frequent or infrequent in 2014: with a frequency lower than .1 or higher than .2.
#filter out
voornamen_data_selection <- voornamen_data %>%
filter((per > 0.1) & (per < .2))
voornamen_data_selection %>%
filter(is_girl_name == 1) %>%
group_by(names) %>%
filter(row_number()==1) %>%
ungroup() %>%
select(names, number, per) %>%
arrange(desc(per)) %>%
kbl(caption = "Female names in selection \n (Dutch population 2014 = 16.829.289)", col.names = c("Name", "Frequency 2014", "Percentage")) %>%
kable_paper(bootstrap_options = c("hover", "condensed"), full_width = F, fixed_thead = T) %>%
scroll_box(height = "300px")| Name | Frequency 2014 | Percentage |
|---|---|---|
| Esther | 33392 | 0.1984160 |
| Antonia | 32039 | 0.1903764 |
| Ingrid | 31323 | 0.1861219 |
| Christina | 30630 | 0.1820041 |
| Linda | 29955 | 0.1779933 |
| Robin | 29432 | 0.1748856 |
| Elizabeth | 28968 | 0.1721285 |
| Theodora | 28221 | 0.1676898 |
| Sandra | 27680 | 0.1644752 |
| Sanne | 27394 | 0.1627757 |
| Aaltje | 27287 | 0.1621399 |
| Kim | 26055 | 0.1548194 |
| Laura | 25681 | 0.1525971 |
| Grietje | 25634 | 0.1523178 |
| Alida | 25422 | 0.1510581 |
| Marianne | 24671 | 0.1465956 |
| Jolanda | 23652 | 0.1405407 |
| Karin | 23067 | 0.1370646 |
| Jantje | 22884 | 0.1359772 |
| Iris | 22722 | 0.1350146 |
| Trijntje | 22377 | 0.1329646 |
| Eva | 21970 | 0.1305462 |
| Jacqueline | 21771 | 0.1293638 |
| Lisa | 21200 | 0.1259709 |
| Neeltje | 21116 | 0.1254717 |
| Geertje | 20789 | 0.1235287 |
| Bianca | 20518 | 0.1219184 |
| Saskia | 20375 | 0.1210687 |
| Janna | 20351 | 0.1209261 |
| Astrid | 20274 | 0.1204685 |
| Chantal | 19943 | 0.1185017 |
| Wendy | 19563 | 0.1162438 |
| Danielle | 19446 | 0.1155486 |
| Petra | 19336 | 0.1148949 |
| Maaike | 19217 | 0.1141878 |
| Anouk | 19186 | 0.1140036 |
| Judith | 19095 | 0.1134629 |
| Patricia | 19028 | 0.1130648 |
| Antje | 18876 | 0.1121616 |
| Emma | 18730 | 0.1112941 |
| Femke | 18102 | 0.1075625 |
| Nicole | 18094 | 0.1075149 |
| Lotte | 17675 | 0.1050252 |
| Ellen | 17210 | 0.1022622 |
| Willemina | 17133 | 0.1018047 |
| Gerarda | 17120 | 0.1017274 |
| Jannetje | 17001 | 0.1010203 |
| Francisca | 16944 | 0.1006816 |
voornamen_data_selection %>%
filter(is_girl_name == 0) %>%
group_by(names) %>%
filter(row_number()==1) %>%
ungroup() %>%
select(names, number, per) %>%
arrange(desc(per)) %>%
kbl(caption = "Male names in selection \n (Dutch population 2014 = 16.829.289)", col.names = c("Name", "Frequenty 2014", "Percentage")) %>%
kable_paper(full_width = F, bootstrap_options = c("hover", "condensed"), fixed_thead = T) %>%
scroll_box(height = "300px")| Name | Frequenty 2014 | Percentage |
|---|---|---|
| Mark | 33618 | 0.1997589 |
| Patrick | 31984 | 0.1900496 |
| Albert | 31767 | 0.1887602 |
| Arie | 31685 | 0.1882730 |
| Martijn | 30193 | 0.1794075 |
| Tim | 30153 | 0.1791698 |
| Robin | 29432 | 0.1748856 |
| Paul | 28958 | 0.1720691 |
| Erik | 28852 | 0.1714392 |
| Maarten | 28703 | 0.1705538 |
| Bernardus | 27851 | 0.1654912 |
| Wouter | 27302 | 0.1622291 |
| Marco | 26958 | 0.1601850 |
| Sander | 26800 | 0.1592462 |
| Bart | 26183 | 0.1555800 |
| Alexander | 26020 | 0.1546114 |
| Niels | 25537 | 0.1517414 |
| Michael | 25405 | 0.1509571 |
| Paulus | 25326 | 0.1504876 |
| Frank | 24816 | 0.1474572 |
| Leonardus | 24628 | 0.1463401 |
| Klaas | 24357 | 0.1447298 |
| Christiaan | 23844 | 0.1416816 |
| Albertus | 23591 | 0.1401782 |
| Kevin | 23167 | 0.1376588 |
| Tom | 22988 | 0.1365952 |
| Michel | 22762 | 0.1352523 |
| Daan | 22704 | 0.1349077 |
| Edwin | 21866 | 0.1299282 |
| Frederik | 21490 | 0.1276940 |
| Leendert | 20913 | 0.1242655 |
| Hans | 20810 | 0.1236535 |
| Adriaan | 20628 | 0.1225720 |
| Hubertus | 20527 | 0.1219719 |
| Ruben | 20417 | 0.1213183 |
| Stefan | 20375 | 0.1210687 |
| Gerard | 20165 | 0.1198209 |
| Lars | 20135 | 0.1196426 |
| Bram | 20072 | 0.1192683 |
| Martin | 20061 | 0.1192029 |
| Lucas | 20049 | 0.1191316 |
| Thijs | 20016 | 0.1189355 |
| Rudolf | 19890 | 0.1181868 |
| Roy | 19856 | 0.1179848 |
| Robertus | 19799 | 0.1176461 |
| Herman | 19607 | 0.1165052 |
| Jasper | 19454 | 0.1155961 |
| David | 19142 | 0.1137422 |
| Nick | 19098 | 0.1134807 |
| Hermanus | 19025 | 0.1130470 |
| Rick | 18834 | 0.1119120 |
| Eric | 18735 | 0.1113238 |
| Bas | 18709 | 0.1111693 |
| Roelof | 18502 | 0.1099393 |
| Harm | 18344 | 0.1090004 |
| Lambertus | 18182 | 0.1080378 |
| Simon | 17949 | 0.1066533 |
| Josephus | 17844 | 0.1060294 |
| Joseph | 17492 | 0.1039378 |
| Mike | 17351 | 0.1031000 |
| Danny | 17029 | 0.1011867 |
| Max | 17024 | 0.1011570 |
| Joost | 16941 | 0.1006638 |
| Geert | 16890 | 0.1003607 |
Popularity heatmaps
It is important that the names provide an overview of the population that we want to scale up to. This means that we want our set of names to be representative in terms of age, as naming preferences are structured by period. For instance, we will introduce bias when we only choose names that were popular in the 50s. Luckily, we can easily show these patterns with heatmaps of the percentage of newborns with a given name in a given year. When we order the names in the heatmap by age we can easily see the age structure of names.
#first, before we make the plot we need to create an order in the plot.
#what we want is to have the names ordered by time where they were mos popular.
#create test procedure for just one name (Anne)
#idea is to first create rolling average of 6 years.
name_order <- voornamen_data_selection %>%
group_by(names) %>%
mutate(rol_average = zoo::rollmean(value_list, k = 6, fill = NA)) %>%
#look for min roll average within names (lower rank means higher popularity)
mutate(max_average = max(rol_average, na.rm = T)) %>%
#filter for min roll average
filter(rol_average == max_average) %>%
#rename year into min_year. With this we can arrange the data later on.
rename(max_year = year_list) %>%
#only select name and min_year.
select(names, max_year) %>%
ungroup()
#we still have multiple cases for several names.
#so we choose the earliest observation per name.
name_order %<>%
arrange(names) %>%
group_by(names) %>%
arrange(max_year) %>%
#choose the first observation
filter(row_number()==1) %>%
ungroup()
#let's add this data to the voornamen_data_selection file.
voornamen_data_selection %<>%
left_join(name_order, by = "names")
#let's create the heatplot for female names.
#first, let's reorder the factor names based on min_year.
voornamen_data_selection$names <- factor(voornamen_data_selection$names)
voornamen_data_selection$names <- fct_reorder(voornamen_data_selection$names,voornamen_data_selection$max_year)voornamen_data_selection %>%
filter(is_girl_name == 1 & year_list > 1940) %>%
ggplot(aes(x = year_list, y = names, fill = value_list)) +
geom_tile() +
theme_minimal() +
theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust=1)) +
scale_x_continuous(breaks = 1940:2016) +
scale_fill_continuous(type = "viridis") +
labs(title = "Heatmap of popularity female names of newborn in the Netherlands (1920-2016)", caption = "Source: Meertens Instituut (2016)")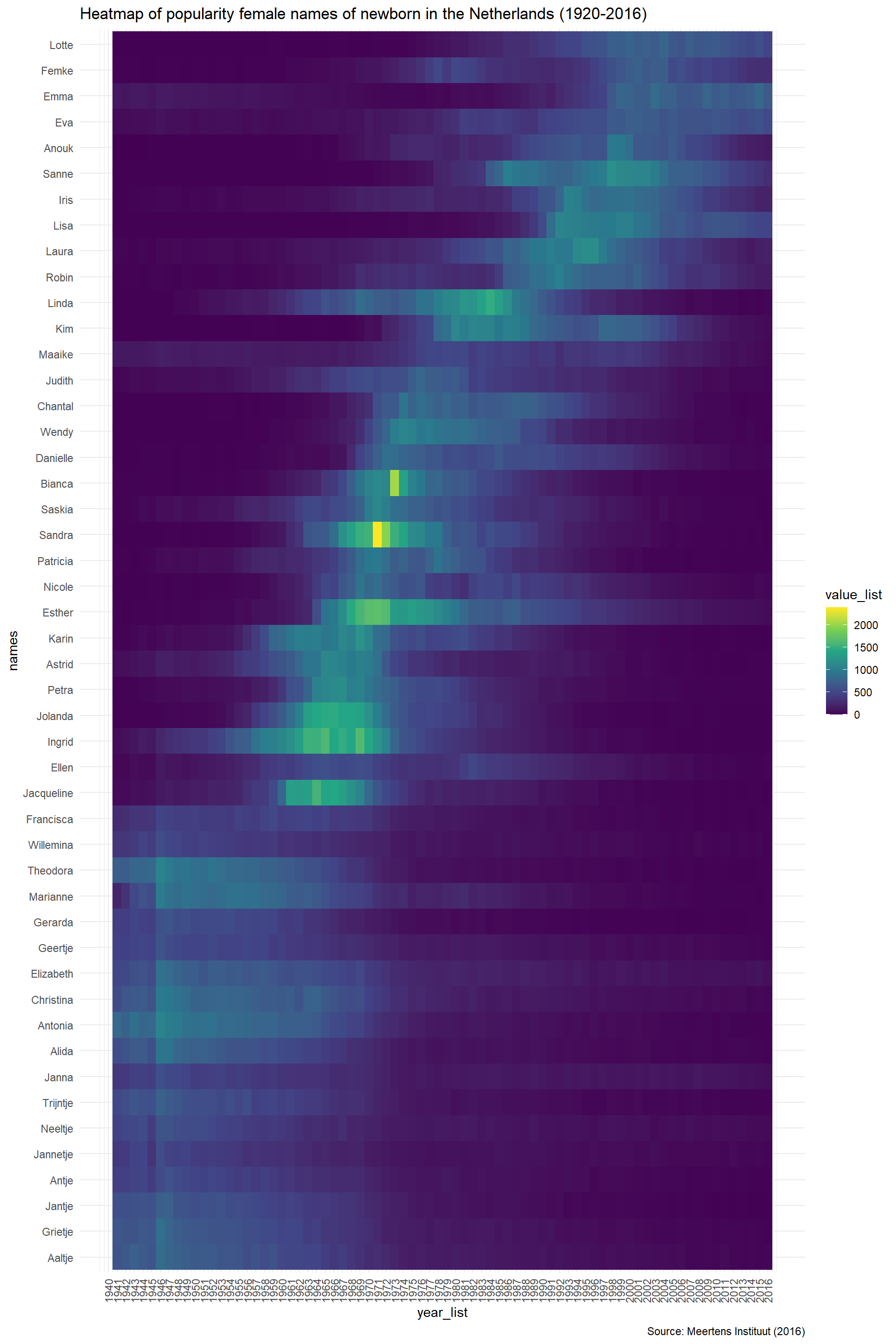
voornamen_data_selection %>%
filter(is_girl_name == 0 & year_list > 1940) %>%
ggplot(aes(x = year_list, y = names, fill = value_list)) +
geom_tile() +
theme_minimal() +
theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust=1)) +
scale_x_continuous(breaks = 1940:2016) +
scale_fill_continuous(type = "viridis") +
labs(title = "Heatmap of popularity male names of newborn in the Netherlands (1920-2014)", caption = "Source: Meertens Instituut (2016)")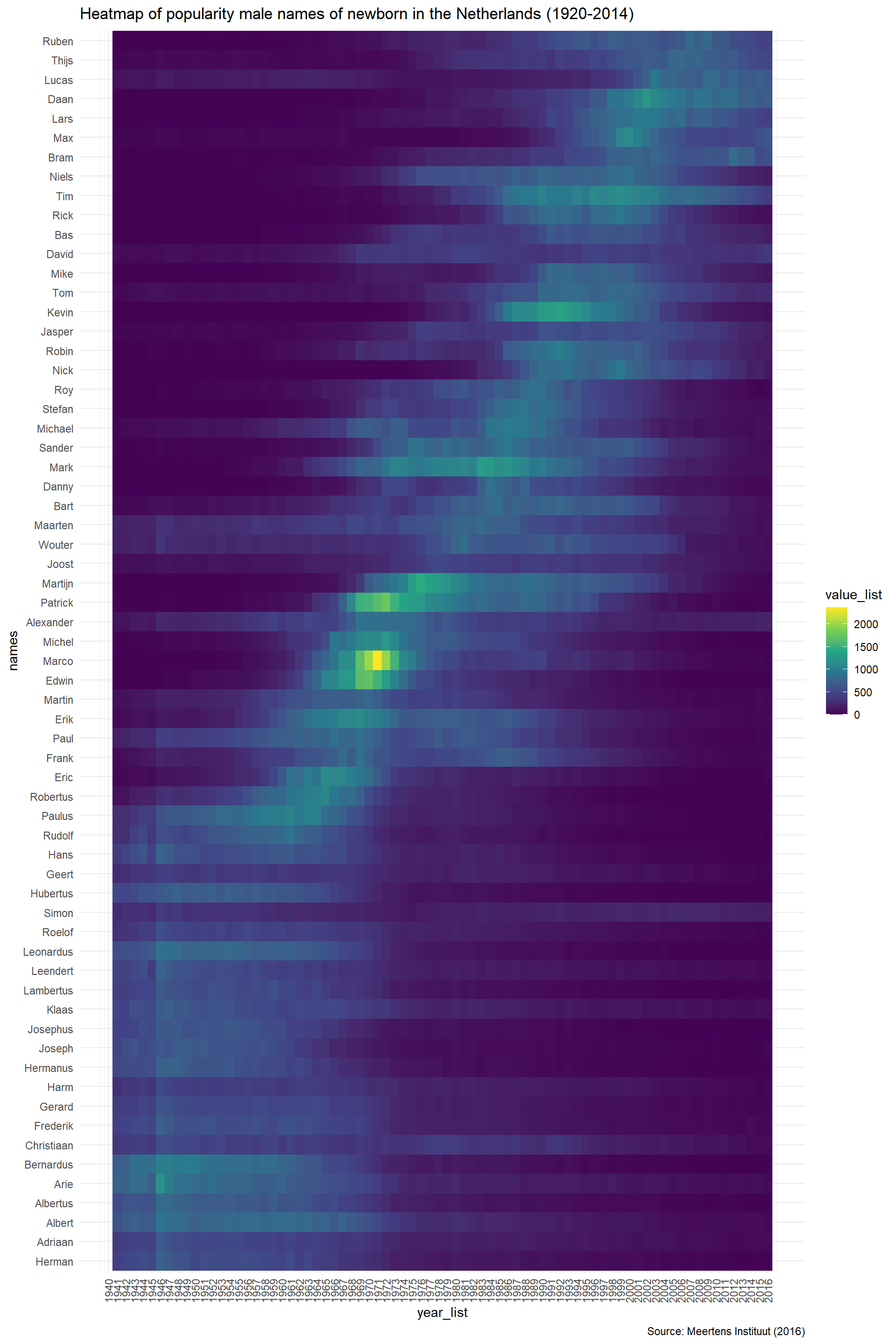
Selection of names
Based on the heat map and the frequency of names I have chosen the following names. Additionally, I also took into account the socioeconomic status of names. I tried to keep a balance of high and low status names to reduce bias in the results. (Bloothooft and Groot 2008; “Socioeconomic Determinants of First Names: Names: Vol 59, No 1” n.d.).
Male names
| < 25 years old | 25-40 | 40-65 | 65+ | |
|---|---|---|---|---|
| Male | Daan | Kevin | Edwin | Albert |
| Female | Emma | Linda | Ingrid | Willemina |
For now we have a selection of 16 names. We will add 4 ethnic names to this mix, 2 names with Moroccan origin and 2 names with turkish origin. For these we need a seperate name analyses, which will be done in the next section.
Ethnic Names
For the development of the NELLS questionnaire we would also like to include ethnic names so we can capture the ethnic segregation of a network. For this purpose we also made the same frequency analysis for ethnic names. To scrape the Meertens data bank we need a list of names that can be classified as Turkish or Moroccan, since these are the two ethnic minorities we over-sample in the NELLS. I used a publication of Bloothooft and Groot that was published in 2005. They describe the clustering of names in the Netherlands and in the appendix of this study they provide all the names in each cluster. I used the names from the Turkish and the Arabic clusters to scrape the Meertens databank.
ethnic_names <- read_csv("data_analysis/data/data_processed/meertens_scrape/bloothooft_names_frequency_18802016.csv")Name frequency
Let’s check the frequency of Turkish and Moroccan names in 2014 for male and females respectively. The histogram clearly shows that for these ethnic names we need other criteria for name frequency, since all names do not meet the criteria of .1 or .2 overall frequency.
#create percentage variable
ethnic_names <- ethnic_names %>%
mutate(n = 16829289,
per = (n_total / n) * 100)
#check the over distribution of percentages
ethnic_names %>%
group_by(names) %>%
summarise(percentage = max(per),
is_female = max(gender) - 1,
ethnicity = max(ethnicity)) %>%
arrange(desc(percentage)) %>%
ggplot(aes(x = percentage)) +
geom_histogram() +
theme_minimal() +
facet_wrap(vars(is_female, ethnicity)) +
labs(title = "Distribution of name frequency for Turkish and Moroccan \nfemale and male first names")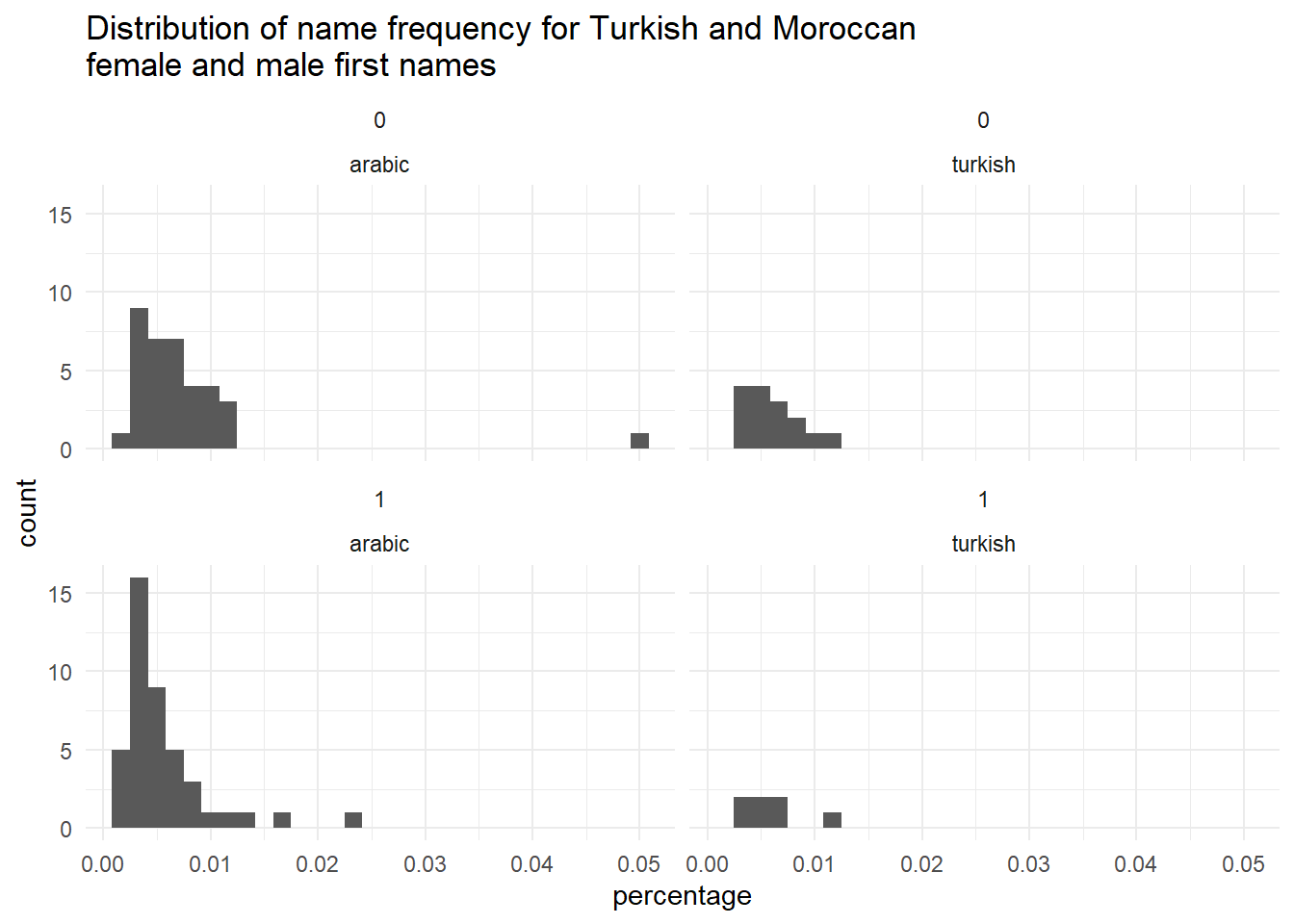
If we do filter with these values we literally get zero rows. So no ethnic names are frequent enough if we use the same heuristic for choosing dutch names; especially Turkish names are less frequent. So we need a way to take a sample of these names. For now, a simple heuristic. Take names that are one standard deviation more frequent than the mean frequency per category (ethnicity/gender). This means we select the most frequent ethnic names.
ethnic_names_summarized <- ethnic_names %>%
group_by(names) %>%
summarise(percentage = max(per),
is_female = max(gender) - 1,
ethnicity = max(ethnicity)) %>%
ungroup() %>%
group_by(ethnicity, is_female) %>%
mutate(mean_percentage = mean(percentage),
sd_percentage = sd(percentage)) %>%
ungroup()
#filter based on +1 sd above mean frequency.
sample <- ethnic_names_summarized %>%
filter(percentage > (mean_percentage + sd_percentage)) %>%
select(names)
#extract the sample from the name_data.
final_sample <- ethnic_names %>%
filter(names %in% sample$names)
final_sample %>%
filter(gender == 2) %>%
select(names, n_total, per, ethnicity) %>%
arrange(desc(per)) %>%
distinct() %>%
kbl(caption = "Female Turkish and Arabic names in selection \n (Dutch population 2014 = 16.829.289)", col.names = c("Name", "Frequency 2014", "Percentage", "Ethnicity")) %>%
kable_paper(bootstrap_options = c("hover", "condensed"), full_width = F, fixed_thead = T) %>%
scroll_box(height = "300px")| Name | Frequency 2014 | Percentage | Ethnicity |
|---|---|---|---|
| Nadia | 3956 | 0.0235066 | arabic |
| Fatima | 2808 | 0.0166852 | arabic |
| Samira | 2186 | 0.0129893 | arabic |
| Yasmine | 1919 | 0.0114027 | arabic |
| Esra | 1878 | 0.0111591 | turkish |
final_sample %>%
filter(gender == 1) %>%
select(names, n_total, per, ethnicity) %>%
arrange(desc(per)) %>%
distinct() %>%
kbl(caption = "Male Turkish and Arabic names in selection \n (Dutch population 2014 = 16.829.289)", col.names = c("Name", "Frequency 2014", "Percentage", "Ethnicity")) %>%
kable_paper(bootstrap_options = c("hover", "condensed"), full_width = F, fixed_thead = T) %>%
scroll_box(height = "300px")| Name | Frequency 2014 | Percentage | Ethnicity |
|---|---|---|---|
| Mohamed | 8445 | 0.0501804 | arabic |
| Ibrahim | 2099 | 0.0124723 | turkish |
| Emre | 1582 | 0.0094003 | turkish |
| Yusuf | 1497 | 0.0088952 | turkish |
Birth frequency heatmaps
Same as with the native dutch names we can create heatmaps to look for a relationship between name and age.
#first, before we make the plot we need to create an order in the plot.
#we have the birth frequency per year of a given name.
#create rolling average of 6 years.
name_order <- final_sample %>%
group_by(names) %>%
mutate(rol_average = zoo::rollmean(value_list, k = 6, fill = NA)) %>%
#look for max roll average within names
mutate(max_average = max(rol_average, na.rm = T)) %>%
#filter for min roll average
filter(rol_average == max_average) %>%
#rename year into min_year. With this we can arrange the data later on.
rename(min_year = year_list) %>%
#only select name and min_year.
select(names, min_year) %>%
ungroup()
#we still have multiple cases for several names.
#so we choose the earliest observation per name.
name_order %<>%
arrange(names) %>%
group_by(names) %>%
arrange(min_year) %>%
#choose the first observation
filter(row_number()==1) %>%
ungroup()
#let's add this data to the voornamen_data_selection file.
final_sample %<>%
left_join(name_order, by = "names")
#let's create the heatplot for female names.
#first, let's reorder the factor names based on min_year.
final_sample$names <- factor(final_sample$names)
final_sample$names <- fct_reorder(final_sample$names,final_sample$min_year)heatmap_male_turkish <- final_sample %>%
filter((gender == 1) & (year_list > 1920)& (ethnicity == "turkish")) %>%
ggplot(aes(x = year_list, y = names, fill = value_list)) +
geom_tile() +
theme_minimal() +
theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust=1),
legend.position = "none") +
# scale_x_continuous(breaks = final_sample$year_list) +
scale_fill_continuous(type = "viridis") +
labs(title = "Male Turkish Names")
heatmap_female_turkish <- final_sample %>%
filter((gender == 2) & (year_list > 1920)& (ethnicity == "turkish")) %>%
ggplot(aes(x = year_list, y = names, fill = value_list)) +
geom_tile() +
theme_minimal() +
theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust=1)) +
# scale_x_continuous(breaks = final_sample$year_list) +
scale_fill_continuous(type = "viridis") +
labs(title = "Female Turkish Names")
heatmap_male_moroccan <- final_sample %>%
filter((gender == 1) & (year_list > 1920)& (ethnicity == "arabic")) %>%
ggplot(aes(x = year_list, y = names, fill = value_list)) +
geom_tile() +
theme_minimal() +
theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust=1),
legend.position = "none") +
# scale_x_continuous(breaks = final_sample$year_list) +
scale_fill_continuous(type = "viridis") +
labs(title = "Male Arabic Names")
heatmap_female_moroccan <- final_sample %>%
filter((gender == 2) & (year_list > 1920)& (ethnicity == "arabic")) %>%
ggplot(aes(x = year_list, y = names, fill = value_list)) +
geom_tile() +
theme_minimal() +
theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust=1)) +
# scale_x_continuous(breaks = final_sample$year_list) +
scale_fill_continuous(type = "viridis") +
labs(title = "Female Arabic Names", caption = "Source: Meertens Instituut (2016)")
heatmap_male_turkish + heatmap_female_turkish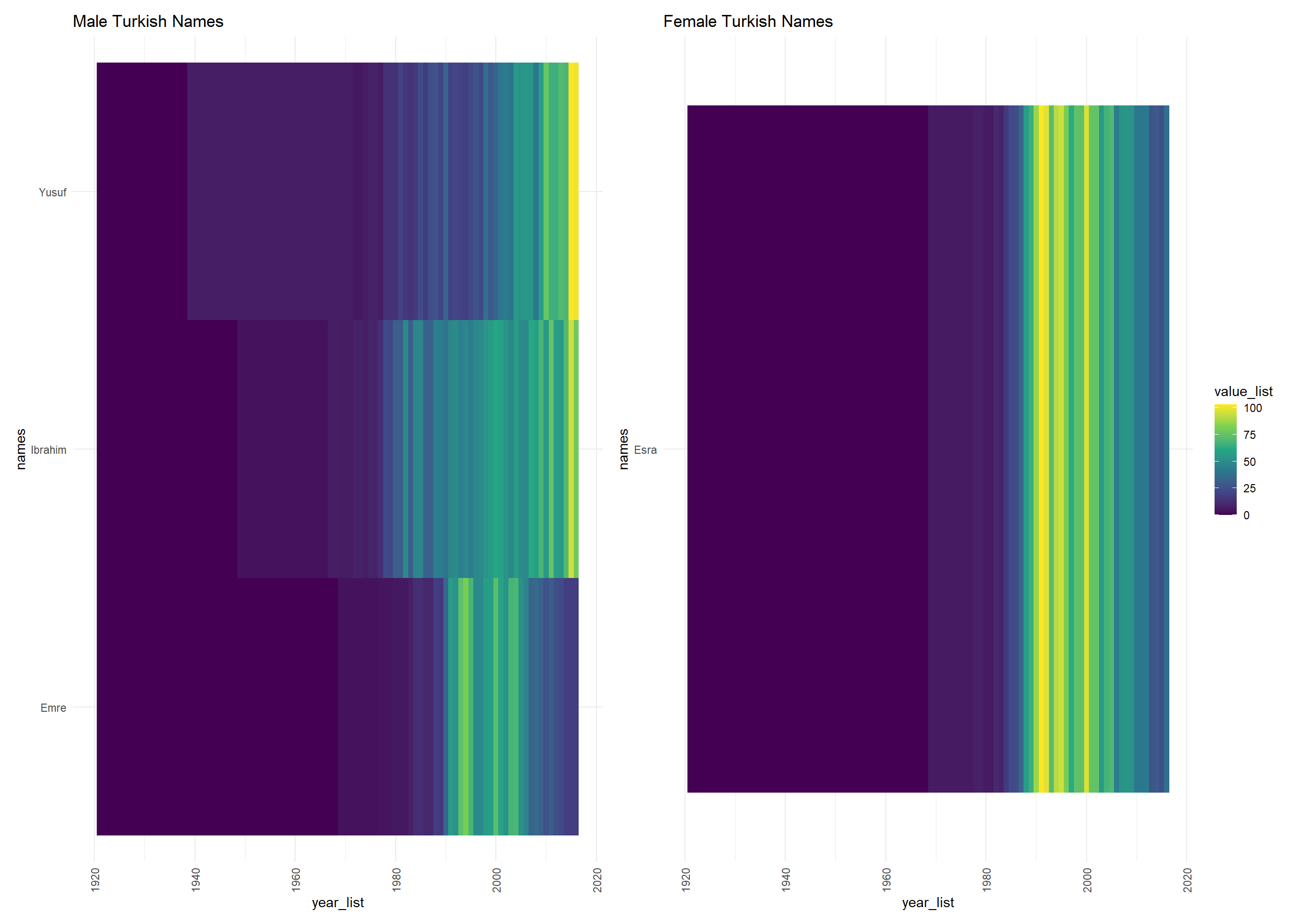
heatmap_male_moroccan + heatmap_female_moroccan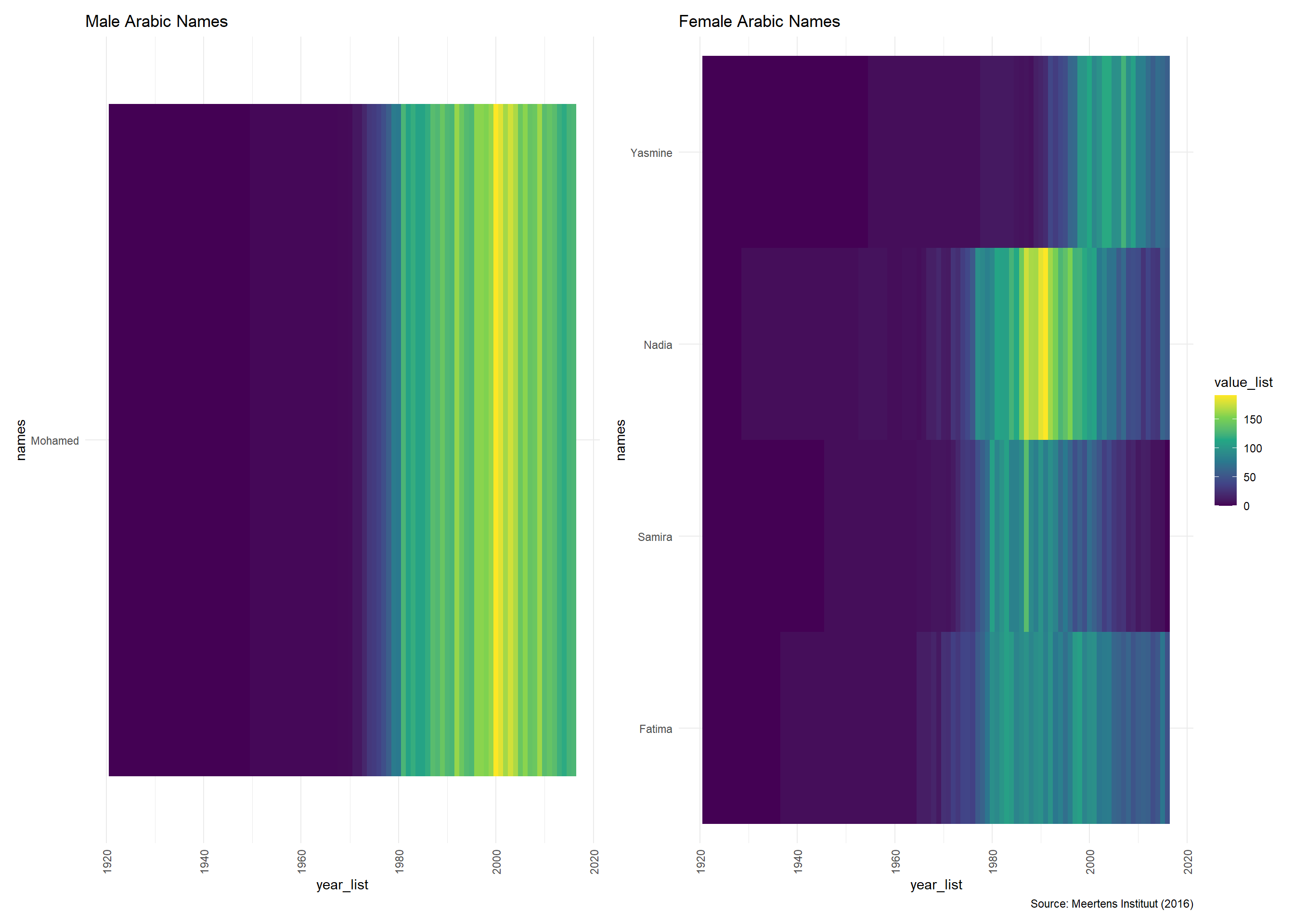
These heat maps show that for most of the Moroccan and Turkish names there is no clear relationship with age. Also, the number of names to choose from is rather low. So, I would propose to select the names that are highly prevalent in these four categories. Also, when we take a look at the demographic profile, in this case the percentage of Dutch citizens with a Turkish or Moroccan migration background we see that only ~4% of the population falls in one of those two categories.
toc <- cbs_get_toc(Language="en") # retrieve only english tables
#select the table that I want. Odata site gives 37296ned as code.
cbs_demo <- cbs_get_data("37296eng")
#let's check the demographic comoposition of the Netherlands in 2021.
cbs_demo %<>%
filter(Periods == "2020JJ00")
#calculate percentage
cbs_demo %>%
select(Morocco_35, Turkey_38, TotalPopulation_1) %>%
mutate(per_mar = (Morocco_35/TotalPopulation_1) * 100,
per_turk = (Turkey_38/TotalPopulation_1) * 100) %>%
kbl(caption = "Turkish and Moroccan minorities in Dutch population (2021) Source: CBS Odata API", col.names = c("N Moroccans", "N Turks", "N population", "% Moroccans", "%Turks")) %>%
kable_paper(bootstrap_options = c("hover", "condensed"), full_width = F, fixed_thead = T) %>%
scroll_box(height = "300px")| N Moroccans | N Turks | N population | % Moroccans | %Turks |
|---|---|---|---|---|
| 408864 | 416864 | 17407585 | 2.348769 | 2.394726 |
My proposal would be to select four ethnic names, each representing one of the groups ethnicity/gender. So I would propose, based on these data: Ibrahim and Esra for Turkish male and female names. For Moroccan male and female names I would choose Mohammed and Fatima.
Final Names
For the survey we have a list of 12 names that we will use. These are:
- Daan
- Kevin
- Edwin
- Albert
- Emma
- Linda
- Ingrid
- Willemina
- Mohammed
- Fatima
- Esra
- Ibrahim
References
Copyright © 2024 Jeroense Thijmen